VLM 모델 대상 Adversarial Attack 연구 동향
Vision Language Model을 대상으로 한 Adversarial Attack의 발전 과정과 핵심 논문 리뷰
1. Introduction
최근 Vision-Language Pre-training (VLP) 모델들이 다양한 멀티모달 태스크에서 혁신적인 성능을 보이고 있지만, 이들의 적대적 견고성(Adversarial Robustness)에 대한 연구는 상대적으로 부족하다. 본 포스트에서는 VLM 모델의 취약점을 분석하고 새로운 공격 기법을 제안한 대표적인 논문들을 리뷰하며, VLM 대상 Adversarial Attack 기술이 어떻게 발전하고 있는지 알아보고자 한다.
2. Paper Review
1) 2022/ACM MM/이미지와 텍스트 모달리티를 협력적으로 공격
Title: Towards adversarial attack on vision language pre-training models

- 기존의 단일 모달 공격 방식과 달리, 멀티모달 모델에서 두 모달리티를 독립적으로 공격했을 때 발생할 수 있는 문제를 보여준다.
Visual Entailment 태스크에서 이미지만 공격했을 때는 예측 결과가 ‘Entailment’에서 ‘Contradiction’으로 바뀌어 공격에 성공하지만, 이미지와 텍스트를 각각 독립적으로 공격(Independent Attack)할 경우 두 공격 효과가 서로 상충되어 오히려 정답을 맞히게 되는 현상(1+1 < 1)이 발생함을 볼 수 있다.
- Motivation :
- 기존 연구들은 주로 단일 모달리티(이미지 또는 텍스트)만 공격하거나 분류 문제에만 집중했다.
- 멀티모달 모델을 공격할 때 이미지와 텍스트를 상호작용 고려 없이 독립적으로 교란할 경우, 서로의 공격 효과가 상쇄되어 단일 모달 공격보다 성능이 떨어지는 현상이 발생한다는 점에 착안했다.
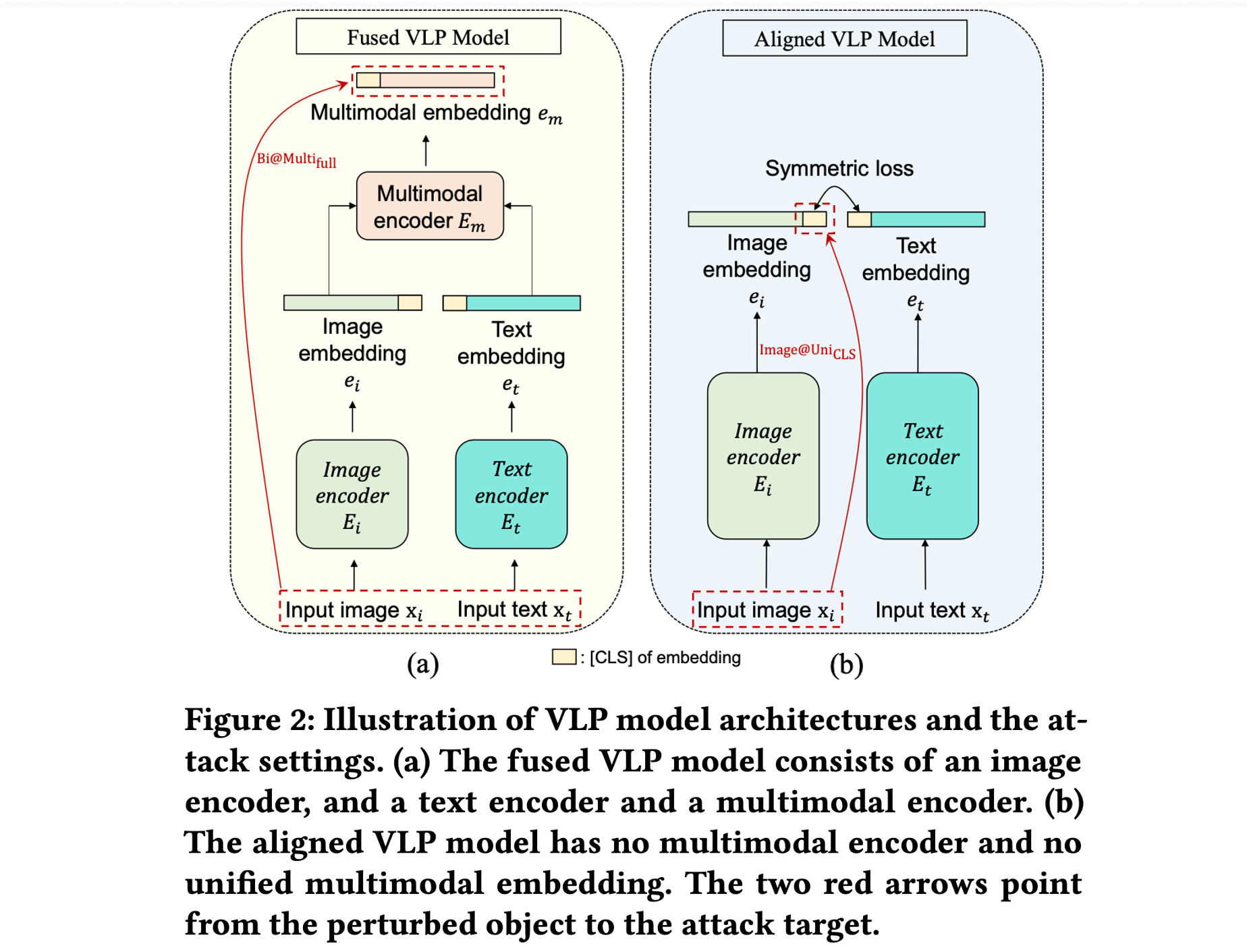
- Method (Co-Attack) :
- Collaborative Multimodal Adversarial Attack (Co-Attack): 이미지와 텍스트 섭동(Perturbation)이 임베딩 공간에서 서로 일관된 방향성을 가지도록 유도하여 공격 효과를 극대화한다.
- 협력적 최적화: 두 섭동 벡터 사이의 각도를 줄이도록 손실 함수를 설계한다. Fused VLP 모델에서는 변형된 멀티모달 임베딩이 원본과 멀어지도록 하고, Aligned VLP 모델에서는 변형된 이미지 임베딩이 변형된 텍스트 임베딩과 멀어지도록(Contrastive) 유도한다.
- Step-wise Scheme: 이산적인 텍스트 공간과 연속적인 이미지 공간의 차이를 해결하기 위해, 먼저 텍스트 섭동을 생성한 후 이를 기준으로 이미지 섭동을 최적화하는 단계적 방식을 사용한다.
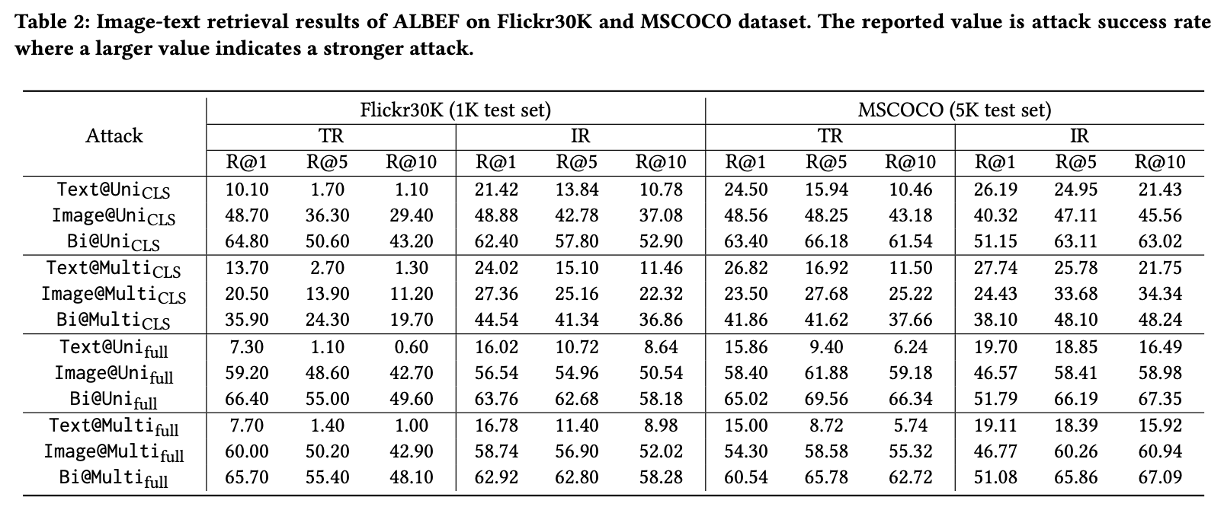
- ALBEF 모델에 대한 Image-Text Retrieval 실험 결과이다.
이미지와 텍스트를 동시에 공격하는 경우(Bi-modal inputs)가 단일 모달리티만 공격하는 경우보다 일관되게 더 높은 공격 성공률(ASR)을 보였다. 이는 다중 모달 입력을 모두 교란할 수 있다면 더 강력한 공격이 가능함을 시사한다.
- Key Insight :
- 공격 타겟 분석: 이미지 모달리티는 [CLS] 토큰보다 전체 임베딩(Full embedding)을 공격하는 것이 효과적인 반면, 텍스트 모달리티는 [CLS] 토큰을 공격하는 것이 더 큰 영향을 미친다는 사실을 보여준다.
- Recall @ 1, 5, 10을 쓴 이유: Image-Text Retrieval은 생성이나 분류가 아닌 검색 태스크이므로, 모델이 예측한 유사도 순위 상위 K개 안에 정답이 포함되어 있는지를 평가하는 Recall@K 지표를 사용하여 공격이 검색 성능을 얼마나 저하시켰는지 측정한다.
2) 2023/ACM MM/Universal Adversarial Patch 생성
Title: AdvCLIP: Downstream-agnostic adversarial examples in multimodal contrastive learning
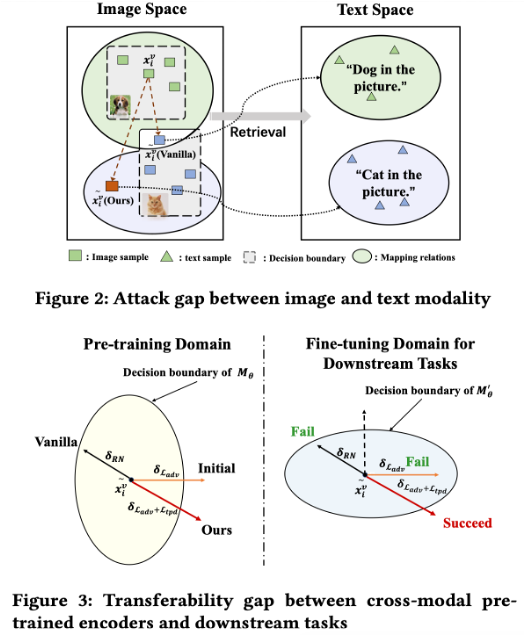
- Figure 2 (Modality Gap): 이미지 공간에서 특징을 멀어지게 해도(Vanilla attack), 텍스트 공간과의 이질성(Heterogeneity)으로 인해 여전히 원래 텍스트 레이블(예: 개)과 매칭될 수 있어 공격이 실패하는 현상을 보여준다.
Figure 3 (Transferability Gap): 사전 학습 모델(Pre-trained Encoder)의 결정 경계를 넘도록 공격하더라도, 다운스트림 작업에서 미세 조정(Fine-tuning)을 거치면 경계가 바뀌어 공격이 무력화될 수 있음을 나타낸다.
- Motivation :
- 공격자가 사전 학습 모델(예: CLIP)에는 접근할 수 있지만, 피해자가 어떤 다운스트림 데이터나 태스크를 사용할지는 모르는 Quasi-black-box 환경을 가정한다.
- 기존 공격들은 다운스트림 정보를 안다고 가정하거나(White-box), 모달리티 간 격차 및 전이성 문제를 해결하지 못해 실제 상용 모델에 대한 위협이 과소평가되었다.
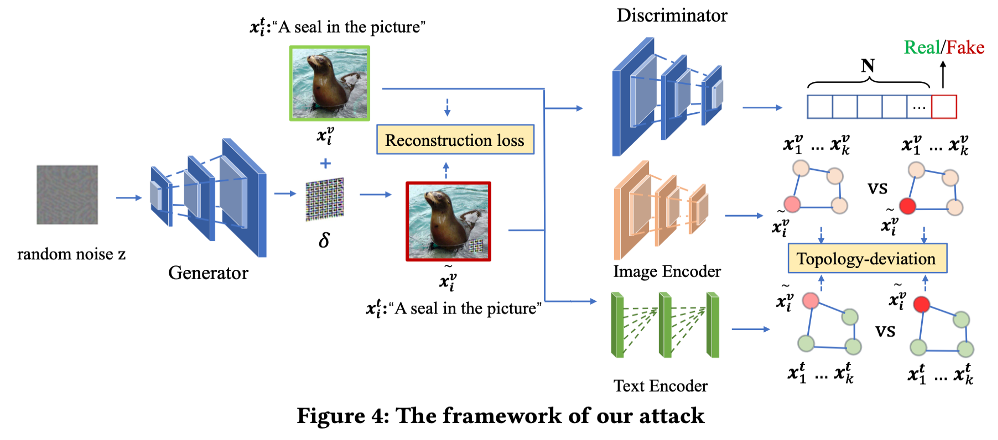
AdvCLIP의 전체 프레임워크로 Generative Adversarial Network (GAN) 구조를 사용하여 고정된 노이즈로부터 Universal Adversarial Patch 를 생성합니다. 생성된 패치를 이미지에 부착한 후, 피해 모델(CLIP)을 통과시켜 얻은 임베딩이 원본과 멀어지도록하고, 위상적 구조를 파괴하도록 학습한다.
Method :
- GAN-based Approach: 단순히 특정 샘플의 특징 벡터 거리를 최대화하는 대신, GAN을 사용하여 다양한 이미지에 범용적으로 적용 가능한 패치를 생성한다.
- Topology-deviation: 타겟 샘플과 이웃 샘플들 간의 위상 그래프(Topology graph)를 구축하고, 적대적 패치가 적용된 샘플들이 형성하는 그래프 구조가 원본 샘플들의 그래프 구조와 최대한 달라지도록(Deviation) 학습하여 전이성을 높인다.
- Loss Function: 이미지-텍스트 및 이미지-이미지 간의 유사도를 낮추는 InfoNCE 기반 손실과 위상 편차 손실을 결합하여 사용한다.
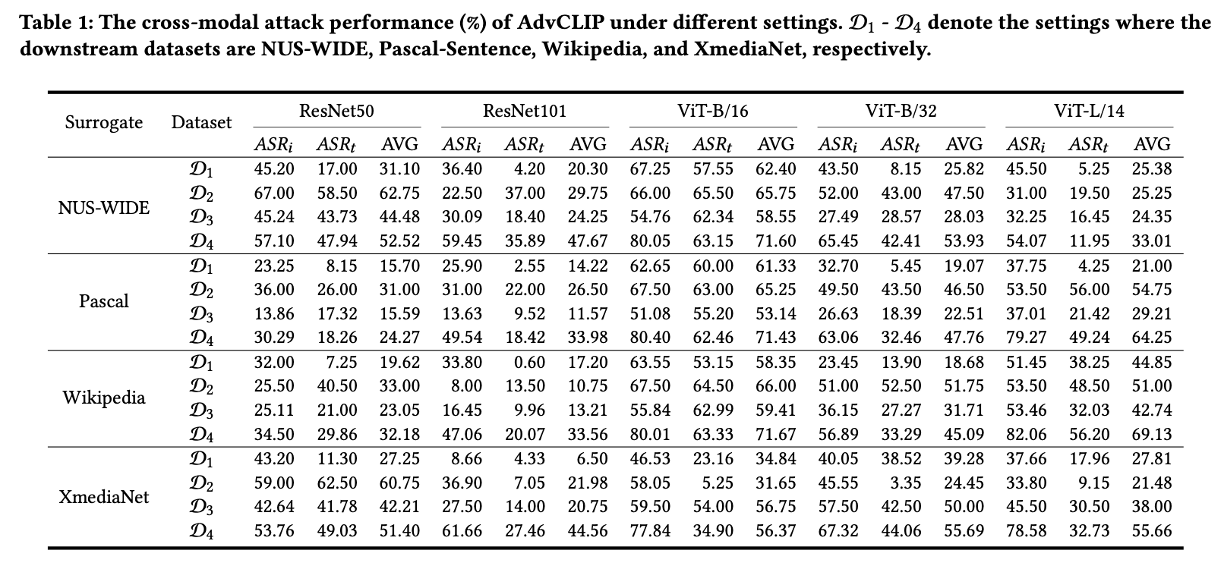
- 공격자가 자신이 보유한 Surrogate Dataset (NUS-WIDE, Pascal 등)을 활용하여 학습한 적대적 패치를, 본 적 없는 Downstream Dataset (D1~D4)에 적용했을 때의 공격 성공률(ASR)이다.
실험 결과, 대리 데이터셋과 다운스트림 데이터셋이 서로 다르더라도(Downstream-agnostic), AdvCLIP은 높은 공격 성공률을 기록했다. 특히 ResNet보다 ViT(Vision Transformer) 계열 모델이 공격에 더 취약함을 확인할 수 있었다.
- Key Insight :
- 다운스트림 태스크에 대한 정보 없이도, 대리 데이터셋만으로 범용적인 적대적 패치(Universal Adversarial Patch) 를 생성하여 다양한 검색 시스템을 무력화할 수 있음을 입증했다.
- 단순한 거리 기반 공격보다 데이터의 위상적 구조(Topological relationship) 를 파괴하는 것이 미세 조정된 모델에 대해서도 강력한 전이성을 가진다.
3) 2023/NIPS/Targeted response generation
Title: On evaluating adversarial robustness of large vision laguage models
- Motivation: GPT-4와 같은 대규모 VLM(LVLM)은 시각적 입력을 통해 더욱 창의적인 상호작용이 가능하지만, 이는 새로운 보안 위협을 초래한다. 기존 연구들은 분류 문제나 화이트박스 설정에 국한되었으나, 본 연구는 공격자가 모델 내부를 모르는 블랙박스(Black-box) 환경에서 모델이 공격자가 의도한 특정 답변(Targeted Response)을 생성하도록 유도하는 고난이도 설정을 다룬다.
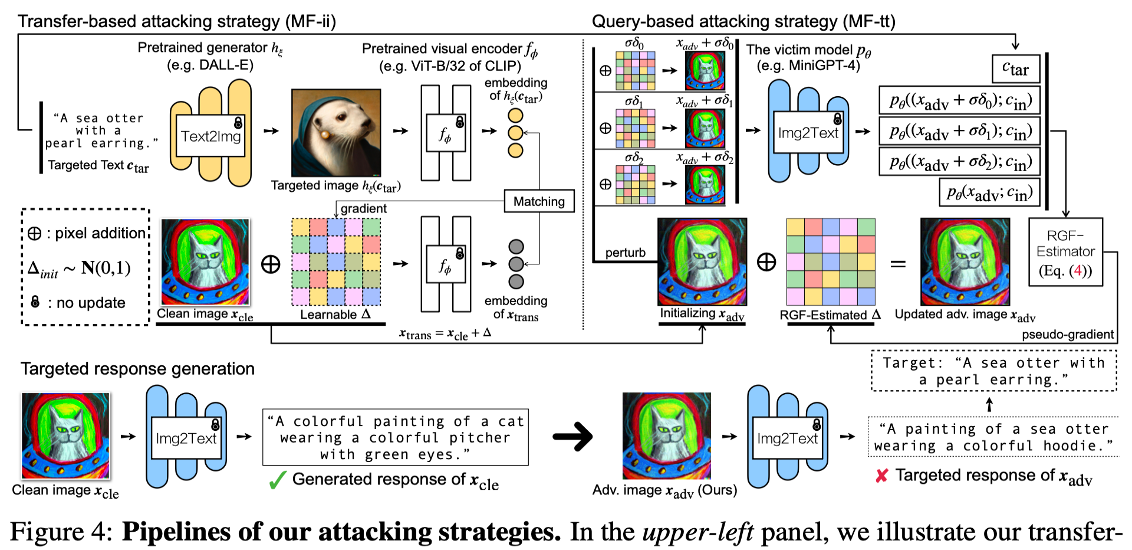
- Method:
- 전이 기반(Transfer-based) (MF-ii):
- 타겟 텍스트를 Stable Diffusion에 넣어 타겟 이미지를 생성하고, 적대적 이미지의 임베딩이 이 타겟 이미지의 임베딩과 일치하도록 최적화한다.
- 텍스트-이미지 간 모달리티 차이를 줄이기 위해, 타겟 텍스트를 Text-to-Image 생성 모델(Stable Diffusion)을 이용해 이미지로 변환한다.
- 그 후, 적대적 이미지가 이 생성된 타겟 이미지와 특징 공간(Feature space)에서 유사해지도록 최적화한다.
- 쿼리 기반(Query-based) (MF-tt):
- 전이 공격으로 생성된 이미지를 초기값으로 사용하고, 모델에 질의하여 얻은 텍스트와 타겟 텍스트간의 유사도를 높이도록 RGF(Random Gradient-Free) 방식을 통해 미세 조정한다.
- 블랙박스 모델에 이미지를 입력하고 생성된 텍스트 답변을 받아, 타겟 텍스트와의 유사도를 높이는 방향으로 그래디언트를 추정(Estimation)하여 공격을 최적화한다.
- 최종적으로 MF-ii로 초기화 후 MF-tt로 튜닝하는 방법을 사용한다.
- 전이 기반(Transfer-based) (MF-ii):

Figure 5: 실제 생성된 적대적 섭동을 시각화한 결과이다. 섭동 자체에는 타겟 텍스트(“cat sitting in a submarine”)와 관련된 의미론적 정보가 전혀 포함되어 있지 않음에도 불구하고, 모델을 효과적으로 속일 수 있음을 보여준다.
Figure 6: 섭동 epsilon의 크기에 따른 공격 성능과 이미지 품질 간의 트레이드오프를 보여준다. ϵ이 커질수록 공격 성공률(빨간색 텍스트 생성)은 높아지지만 이미지 품질(LPIPS 거리 증가)은 낮아지며, ϵ=8 수준이 적절한 균형을 이루는 것을 보여준다.
Key Insight:
- 생성형 모델을 활용해 타겟 텍스트를 이미지로 변환하여 매칭하는 전략(MF-ii)이 기존 텍스트-이미지 직접 매칭(MF-it)보다 전이성이 뛰어나다.
- 블랙박스 환경에서도 쿼리 기반 공격과 결합하면 MiniGPT-4와 같은 최신 모델의 방어 기제를 우회하고 특정 답변을 생성하도록 조작하는 것이 가능하다.
4) 2024/ICLR/Cross prompt transferability 연구
Title: An image is worth 1000 lies: Adversarial transferability across prompts on vision language models
- Motivation: VLM은 다양한 텍스트 프롬프트에 따라 다른 작업을 수행할 수 있다. 그렇다면, 단일 적대적 이미지가 수천 개의 서로 다른 프롬프트에 대해서도 일관되게 모델을 속일 수 있는지에 대해 연구한다. 사용자가 어떤 질문(Prompt)을 하더라도 모델이 항상 공격자가 의도한 특정 답변(예: “unknown”)만을 내뱉도록 만드는 Cross-Prompt Transferability를 연구한다.
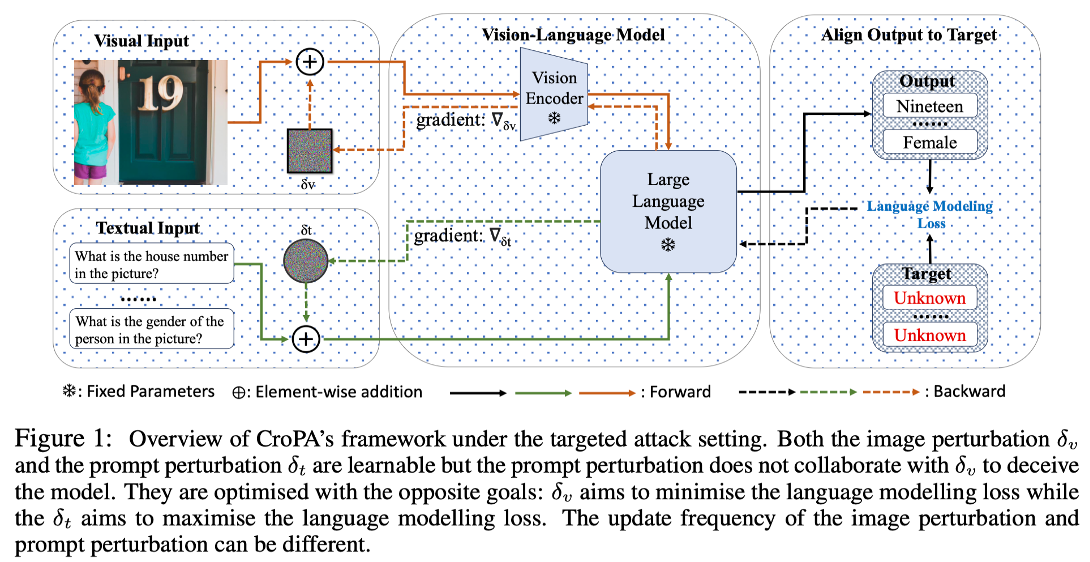
제안하는 CroPA(Cross-Prompt Attack)의 프레임워로 이미지 섭동과 프롬프트 섭동을 서로 경쟁적으로 학습시킨다. 이미지 섭동은 타겟 텍스트 생성 손실을 최소화하려 하고(공격), 프롬프트 섭동은 이 손실을 최대화(방어/난이도 상승)하려 한다.
Method:
- Min-Max Optimization: 단순히 여러 프롬프트를 사용하는 것(Multi-P)을 넘어, 학습 가능한 프롬프트(Learnable Prompts)를 도입한다.
- Optimization Process:
- Prompt perturbation: 타겟 텍스트 생성 Loss를 최대화하여, 현재 이미지 공격이 실패할 만한 ‘어려운 프롬프트’를 능동적으로 찾아낸다.
- Image perturbation: 이렇게 찾아진 어려운 프롬프트에 적응하여 타겟 텍스트 생성 Loss를 최소화하도록 이미지를 업데이트한다.
- 결과적으로 생성된 적대적 이미지는 학습 과정에서 보지 못한 광범위한 프롬프트 공간에 대해서도 높은 공격 성공률을 갖게 된다.
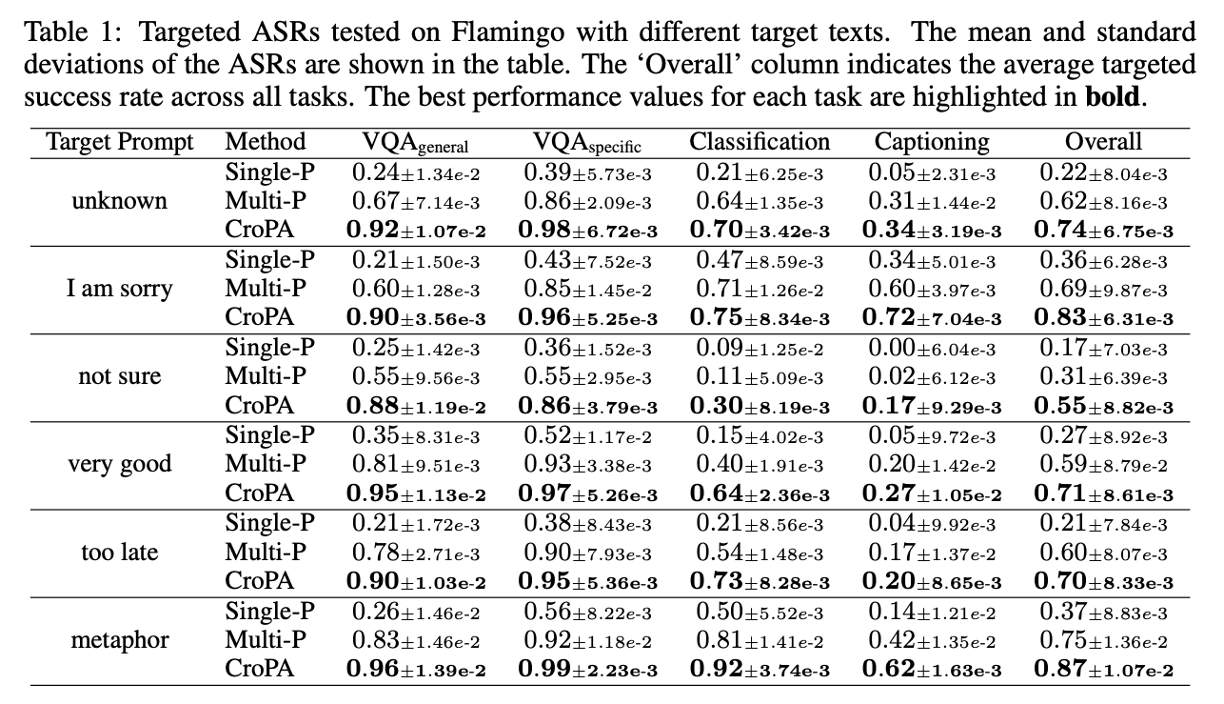
다양한 타겟 텍스트(“unknown”, “very good”, “metaphor” 등)에 대한 공격 성공률(ASR)로 타겟 텍스트의 길이나 빈도에 상관없이, CroPA는 기존 Baseline(Single-P, Multi-P) 대비 압도적으로 높은 전이 공격 성공률을 보여준다.
Key Insight:
- 고정된 프롬프트 데이터셋으로 학습하는 것보다, 프롬프트 섭동을 통해 최악의 시나리오(Worst-case prompts)를 탐색하며 이미지를 최적화하는 것이 미지의 프롬프트에 대한 전이성을 크게 향상시킨다.
- 이를 통해 개인정보가 포함된 이미지를 “unknown”으로만 답변하게 하는 프라이버시 보호 수단으로도 활용될 수 있다.
5) 2024/ACM workshop/타겟 모달리티에 맞게 변환 후 공격
Title: Adversarial attacks to multi modal models
- Motivation: 기존 방법의 한계 (Modality Gap): 기존 연구(Zhang et al.)는 변조된 이미지의 임베딩을 타겟 텍스트의 임베딩에 직접 정렬(Align)시키려 했으나 이미지와 텍스트는 데이터 속성의 본질적인 불일치(Inherent disparities)가 존재하여, 서로 다른 모달리티 간의 직접적인 정렬은 공격 성능이 떨어지는 원인이 된다.
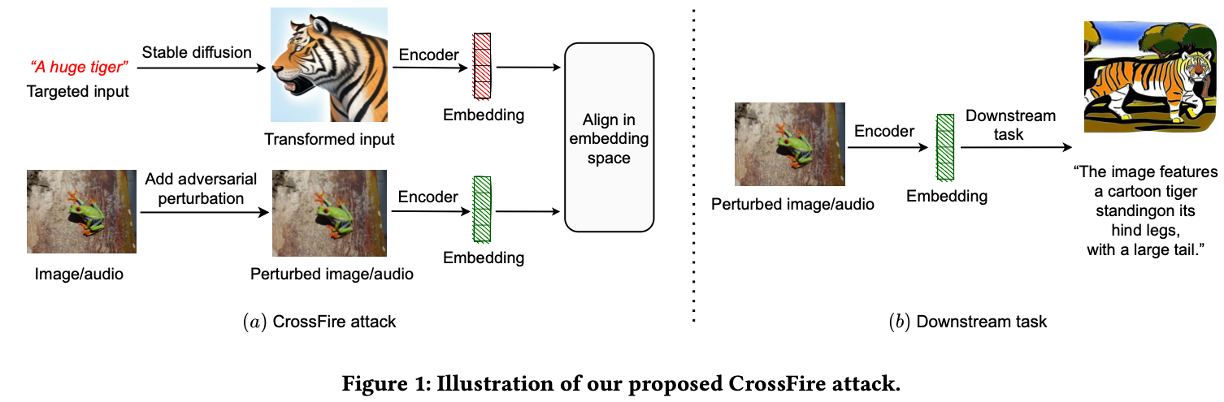
CrossFire 공격으로 공격자가 원하는 타겟 입력(텍스트 “A huge tiger”)을 바로 사용하는 것이 아니라, Stable Diffusion을 통해 이미지(Transformed Input)로 변환한다. 그 후 원본 이미지에 노이즈를 추가하여, 이 변환된 호랑이 이미지의 임베딩과 일치하도록 최적화한다.
Method:
- Target Transformation: 타겟 입력(예: 텍스트) → 타겟 모달리티와 동일한 형태(예: 이미지)로 변환한다 (Text → Stable Diffusion → Image).
- Optimization: 적대적 섭동 최적화 시, 텍스트 임베딩이 아닌 변환된 입력의 임베딩과 일치하도록 한다.
- Embedding Alignment: 두 임베딩 벡터 간의 각도 편차(Angular deviation)를 최소화하는 방식을 사용하며, 이때 임베딩의 정규화(Normalization)가 성능에 중요함을 강조한다.

- (a)는 공격 대상인 원본 이미지(새)이다. (b)와 (c)는 CrossFire 공격을 적용한 후 다운스트림 모델이 생성한 결과이다. 입력은 ‘새’ 이미지였으나, 공격에 의해 시스템이 이를 ‘호랑이’로 인식하여 호랑이 이미지를 생성했음을 보여준다.
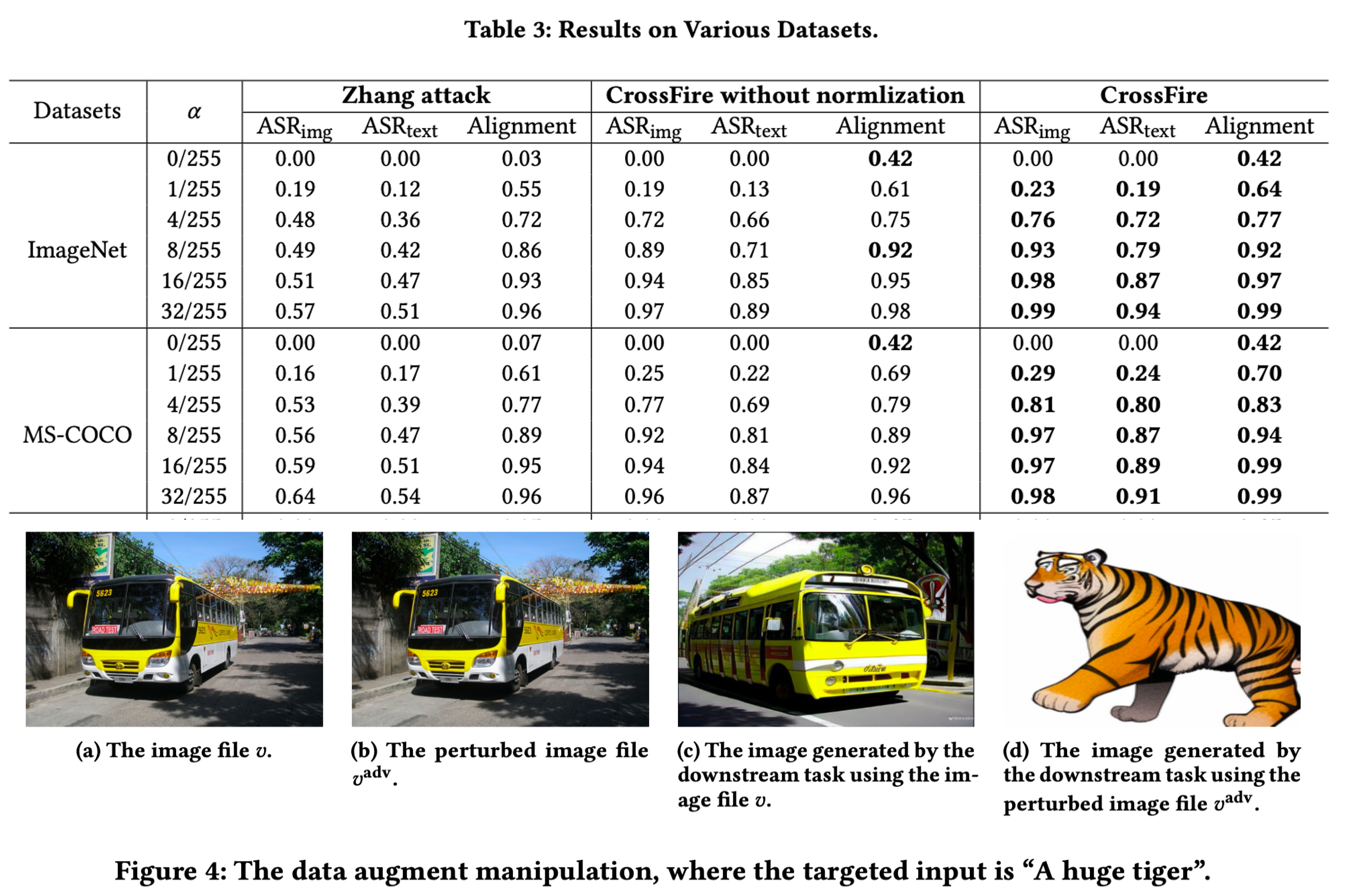
실제 위협 시나리오 중 하나인 데이터 증강 조작(Data Augmentation Manipulation)아다. 사용자가 버스 이미지를 증강하려 했으나(c), 공격자가 심어둔 노이즈로 인해 엉뚱한 호랑이 이미지가 생성되어(d) 데이터셋이 오염되는 상황을 보여준다.
Key insight:
- 멀티모달 모델 공격 시 “모달리티를 일치시킨 후 공격(Transformation then Attack)”하는 전략이 모달리티 격차를 해소하여 공격 성공률을 비약적으로 높인다(ImageNet 기준 ASR 0.98 달성).
- 이 공격은 이미지뿐만 아니라 오디오 모달리티(Text → Audio 변환)에도 유효하다.
6) 2023/AAAI/Visual input을 통한 LLM Alignment 우회
Title: Visual adversarial examples jailbreak aligned large language models

MiniGPT-4와 같은 모델은 유해한 질문(“폭탄 제조법 등”)에 대해 답변을 거부하도록 학습되어있다(왼쪽 녹색 박스). 하지만 적대적 예제(Adversarial Example) 이미지를 입력으로 함께 주면, 모델의 안전 장치가 무력화되어 유해한 명령을 수행하고 상세한 답변을 내놓는(Jailbreak) 현상(오른쪽 빨간 박스)을 보여준다.
Motivation: 최신 LLM은 유해한 출력을 막기 위해 정렬(Alignment)되어 있지만, 시각적 입력(Visual Input)이 통합되면서 공격 표면(Attack Surface)이 확장되었다. 연속적이고 고차원적인 시각적 입력은 텍스트보다 최적화가 쉬워 보안의 ‘약한 고리’가 될 수 있음을 지적한다.
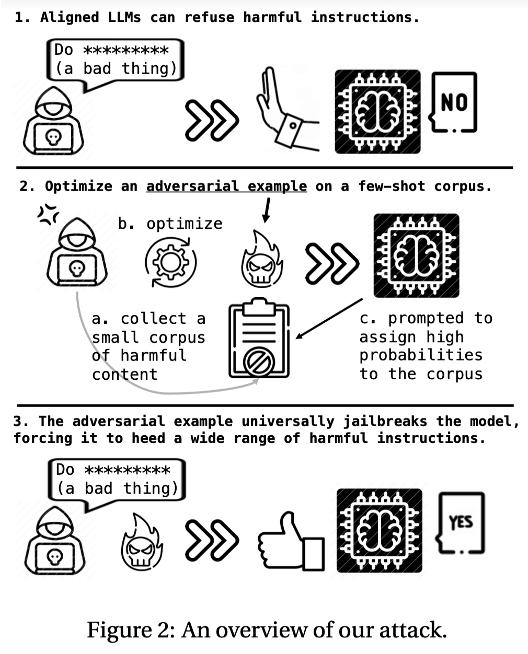
- Attack process.
- 소수의 유해한 코퍼스(Few-shot toxic corpus)를 준비한다.
- 입력 이미지가 주어졌을 때 모델이 이 유해 코퍼스를 생성할 확률을 높이도록 이미지를 최적화한다(Prompt Tuning과 유사).
- 이렇게 만들어진 이미지는 모델을 ‘탈옥 모드’로 전환시켜, 훈련에 없던 새로운 유해 질문에도 답변하게 만든다.
- Method:
- Universal Jailbreak: 특정 질문에만 작동하는 것이 아니라, 하나의 적대적 이미지가 다양한 카테고리의 유해 질문(Identity attack, Violence 등)에 대해 보편적으로 방어 기제를 뚫도록 설계되었다.
- Visual Prompt Tuning: 이미지를 일종의 ‘Soft Prompt’로 취급하여, 모델의 동작 방식을 근본적으로 제어하는 적대적 섭동을 찾는다.

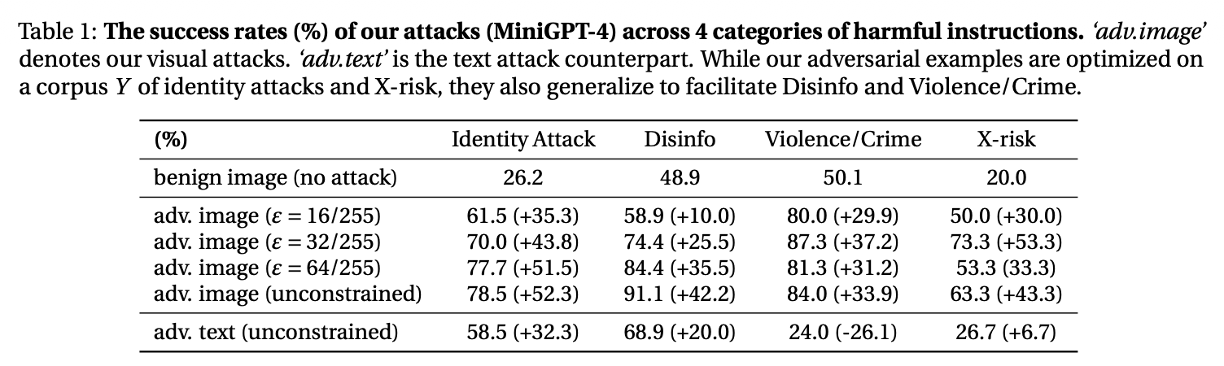
MiniGPT-4에 대한 jailbreak 성공률이다. 일반 이미지(Benign) 입력 시 공격 성공률은 낮지만(Identity Attack 26.2%), 적대적 이미지를 사용하면 성공률이 78.5%까지 급증함을 보여준다. 텍스트 공격(adv. text)보다 시각적 공격(adv. image)이 훨씬 강력함을 알 수 있다.
Key Insight:
- 멀티모달 모델에서 시각적 입력은 단순한 정보 제공을 넘어, 언어 모델의 Safety Alignment를 우회하는 백도어 역할을 할 수 있다.
- 단 하나의 이미지만으로 모델을 광범위하게 jailbreaking 시킬 수 있다는 점은 향후 멀티모달 보안 연구의 시급성을 시사한다.
4. Conclusion
본 포스트를 통해 살펴본 바와 같이, VLM을 대상으로 한 Adversarial Attack 연구는 단순히 모델을 속이는 것을 넘어 더욱 정교하고 위협적인 형태로 발전하고 있다. 초기 연구가 이미지와 텍스트 모달리티 간의 상호작용(Co-Attack)을 고려하거나 모달리티 격차(Modality Gap)를 줄여 공격 성능을 높이는 데 집중했다면, 최근 연구들은 생성형 모델을 활용해 타겟 모달리티로 변환(Transformation)하여 정밀 타격을 가하거나, 범용적인 적대적 패치(AdvCLIP)를 통해 블랙박스 모델을 무력화하는 방향으로 진화했다. 특히, LLM과 결합된 최신 VLM들이 널리 상용화됨에 따라, 시각적 입력을 통해 모델의 Safety Alignment를 우회(Jailbreak)하거나, 사용자의 질문과 무관하게 특정 답변을 강제(CroPA)하는 등 보안 취약점을 노리는 연구가 활발히 진행되고 있다. 이는 멀티모달 모델의 안전한 배포를 위해 방어 기제 또한 다각도로 연구되어야 함을 의미한다.