Scalable Diffusion Models with Transformers
DiT 논문 리뷰
Scalable Diffusion Models with Transformers (arXiv)
Year : 2023
Author : William Peebles, Saining Xie
Conference : ICCV
Motivation
 Motivation.
Motivation.
DiT (Diffusion Transformer)는 기존 U-Net 기반 diffusion 모델보다 더 자연스럽고 고품질의 이미지를 생성할 수 있음을 보여준다.
이는 기존에 diffusion 모델의 성능에 필수적이라고 여겨졌던 U-Net의 inductive bias가 사실 필수적이지 않음을 시사하며, transformer 기반 아키텍처로도 충분히 경쟁력 있는 성능을 낼 수 있음을 증명한다.
- 기존 diffusion 모델의 default backbone이었던 U-Net의 inductive bias를 제거하고자 제안된 모델
- Transformer의 scaling property를 diffusion에 적용하여 성능을 더욱 끌어올림
Inductive Bias
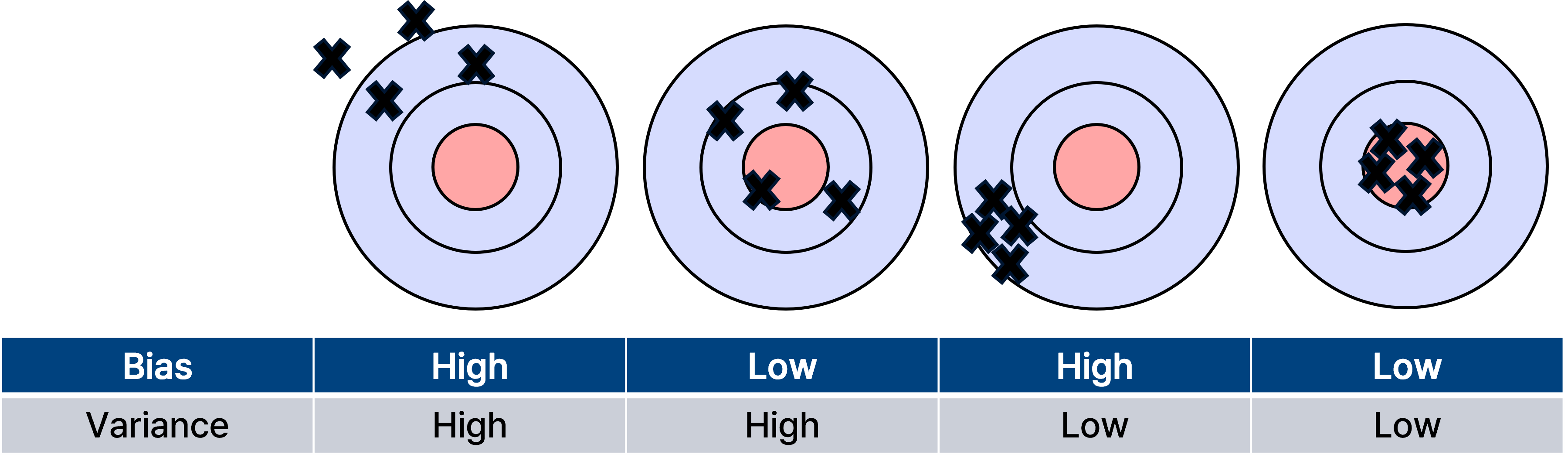 Bias.
Bias.
기본적으로 bias는 타겟과 예측들의 평균의 차이를 의미하며 bias가 크다면 모델의 underfitting 가능성이 높아진다.
이때, inductive bias는 모델이 훈련 시 본 적 없는 입력에 대해 예측을 할 때 사용하는 사전적인 가정(prior assumption)을 의미한다.
모델의 일반화 성능을 높이기 위해 의도적으로 부여되며, 학습 데이터로부터 얻을 수 없는 정보를 보완하는 역할을 한다.
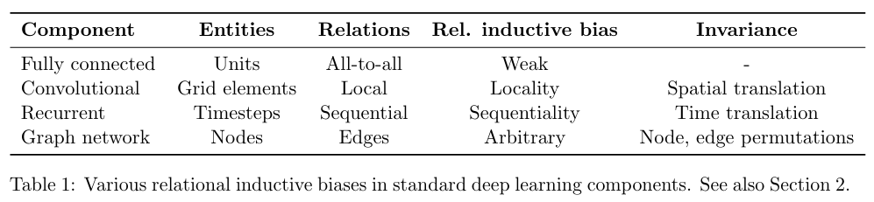 출처 : Google Research “Relational inductive biases, deep learning, and graph networks”.
출처 : Google Research “Relational inductive biases, deep learning, and graph networks”.
이때 google research 에서 발표현 relational inductive biases, deep learning, and graph network 논문에 따르면, vision 정보는 인접 픽셀간의 locality가 존재한다. 따라서 convolutional component는 인접 픽셀간의 정보를 추출하기 위한 목적으로 설계되어 conv의 inductive bias가 local 영역에서 spatial 정보를 잘 뽑아낸다. 이와 반대로 Fully connected 즉 MLP는 all input to all output 관계로 모든 weight가 독립적이며 공유되지 않아 inductive bias가 매우 약하다. 이와 유사하게, transformer는 attention을 통해 입력 데이터의 모든 요소간의 관계를 계산하므로 CNN보다는 inductive bias가 작다.
결론적으로 CNN의 inductive bias는 “locality”에 기반하지만, transformer는 global 관계를 모델링하고 inductive bias가 약하다.
이는 diffusion 모델에서 U-Net의 inductive bias가 없어도 global attention만으로 충분한 표현력을 가질 수 있음을 뒷받침한다.
Scaling Law
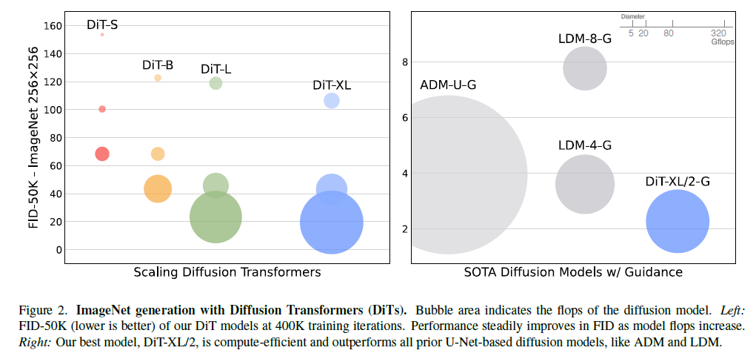 ImageNet generation with Diffusion Transformers.
ImageNet generation with Diffusion Transformers.
기존 U-Net 기반 모델은 모델 크기를 늘릴 때 성능이 포화되는 문제가 있었지만 Transformer의 scaling law에 따라 모델 크기, depth, token 수가 증가할수록 성능이 향상되는 것을 확인할 수 있다.
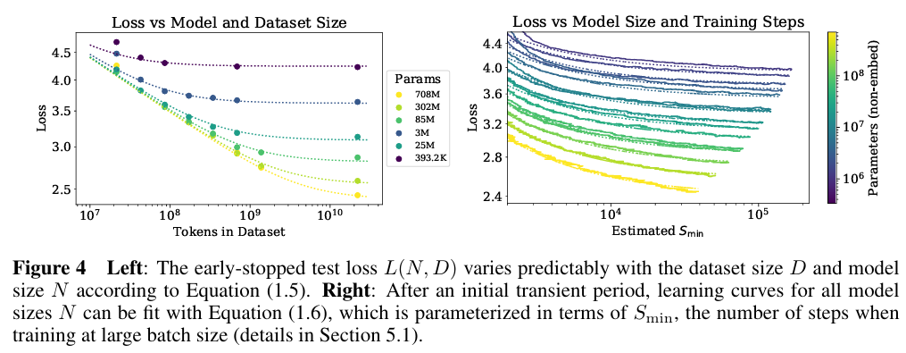 출처 : Scaling Laws for Neural Language Models.
출처 : Scaling Laws for Neural Language Models.
Scaling Laws for Neural Language Models 논문을 통해 transformer은 모델의 크기, 데이터 양, 학습 연산량이 커질수록 성능이 좋아짐을 확인할 수 있다. 이에 Diffusion 모델의 backbone을 Transformer로 대체하면 scaling law의 이점을 diffusion에도 가져올 수 있으며, 더 큰 모델 → 더 많은 token → 더 깊은 layer가 곧 더 좋은 샘플 품질로 이어질 수 있음을 증명한다.
Diffusion
Diffusion formulation(DDPMs)
- Forward Process
Forward Process에서는 깨끗한 이미지에 점진적으로 노이즈를 추가하여 ( x_t )를 만들어간다. 이 과정은 다음과 같은 확률분포로 정의된다:
\[q(x_t | x_0) = \mathcal{N}(x_t; \sqrt{\bar{\alpha}_t} x_0, (1 - \bar{\alpha}_t) I)\]- $x_0$: 원본 이미지
- $\bar{\alpha}_t$: time step $t$에서의 누적 noise scheduling 계수
- $I$: 단위 행렬
이 식은 정규분포로, mean과 variance로 forward 과정의 분포를 정의한다.
또한 reparameterization trick을 사용하여 다음과 같이 샘플링할 수 있다:
\[x_t = \sqrt{\bar{\alpha}_t} x_0 + \sqrt{1 - \bar{\alpha}_t} \, \epsilon_t, \quad \epsilon_t \sim \mathcal{N}(0, I)\]여기서:
- $\epsilon_t$: $\mathcal{N}(0, 1)$로부터 샘플링된 Gaussian noise
forward 과정에서는 깨끗한 데이터 $x_0$에 noise $\epsilon_t$를 점진적으로 섞어 noisy sample $x_t$를 생성한다.
- Backward Process
Backward process는 noisy한 상태 $x_t$로부터 더 clean한 $x_{t-1}$를 복원하는 확률분포를 학습하는 과정이다:
\[p_\theta(x_{t-1} | x_t) = \mathcal{N}(\mu_\theta(x_t), \Sigma_\theta(x_t))\]- $\mu_\theta(x_t)$: neural network가 예측하는 mean
- $\Sigma_\theta(x_t)$: neural network가 예측하는 variance
forward로 노이즈를 추가한 분포를 반대로 되돌리기 위해 mean과 variance를 neural network로 학습한다.
- Loss (Noise Prediction)
Diffusion 모델은 noise 예측 모델로 훈련되며, loss function은 다음과 같다:
\[L_{\text{simple}}(\theta) = \left\| \epsilon_\theta(x_t) - \epsilon_t \right\|^2\]- $\epsilon_\theta(x_t)$: 모델이 예측한 noise
- $\epsilon_t$: ground truth noise
모델은 $x_t$에서 noise를 얼마나 정확하게 예측했는지를 MSE loss로 학습합니다.
Classifier-free guidance
Classifier-free guidance에서는 다음과 같은 gradient를 기반으로 guidance를 적용한다:
\[\nabla_x \log p(c | x) = \nabla_x \log p(x | c) - \nabla_x \log p(x)\]이는 Bayes Rule에서 유도되며, 원하는 조건에 맞는 샘플을 생성하도록 gradient를 조정한다.
| Diffusion 모델의 출력은 사실상 score function $\nabla_x \log p(x | c)$과 유사하다고 해석할 수 있다. |
이때, noise prediction은 다음과 같이 수정된다:
\[\hat{\epsilon}_\theta(x_t, c) = \epsilon_\theta(x_t, \emptyset) + s \left( \epsilon_\theta(x_t, c) - \epsilon_\theta(x_t, \emptyset) \right)\]- $\epsilon_\theta(x_t, \emptyset)$: 조건 없이 (unconditional) 예측된 noise
- $\epsilon_\theta(x_t, c)$: 조건부 (conditional)로 예측된 noise
- $s$: guidance scale (스케일이 1보다 클수록 조건을 더 강하게 반영)
조건 없는 예측과 조건 있는 예측의 차이를 스케일링하여 샘플링 시 조건에 더 부합하도록 조정한다.
예를 들어:
- $s = 1$: 일반적인 샘플링
- $s > 1$: 더 조건에 맞춘 샘플링 (강한 guidance)
Latent diffusion models
고해상도 이미지에서 직접 diffusion을 적용하면 계산량이 매우 크다. 이를 해결하기 위해 최근에는 Latent Diffusion Model (LDM)을 사용하는 추세이다. LDM은 이미지를 먼저 VAE Encoder를 통해 압축된 latent space로 매핑하고, 이 latent 공간에서 diffusion 모델을 학습한다. 이후 샘플링된 latent를 VAE Decoder로 다시 복원하여 최종 이미지를 얻는다. Latent space에서의 연산 덕분에 연산량이 대폭 줄어들면서도 고해상도 이미지를 생성할 수 있다는 장점이 있다.
Proposed Method
Overview
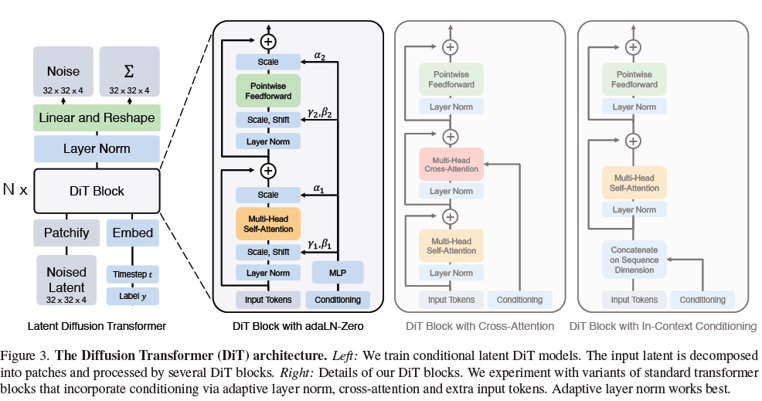 Overview.
Overview.
DiT (Diffusion Transformer)의 전체 pipeline:
- Input Image (256×256×3)
- VAE Encoder → Latent Representation (32×32×4)
- DiT (Transformer 기반의 diffusion model)
- VAE Decoder → 최종 이미지 복원
고해상도 이미지(256x256)를 직접 다루는 대신, VAE로 압축된 latent 공간(32x32x4)에서 diffusion 과정을 수행하여 계산 효율성을 높이고, Transformer를 backbone으로 사용하여 global 관계를 학습한다.
Diffusion Transformer Design Space
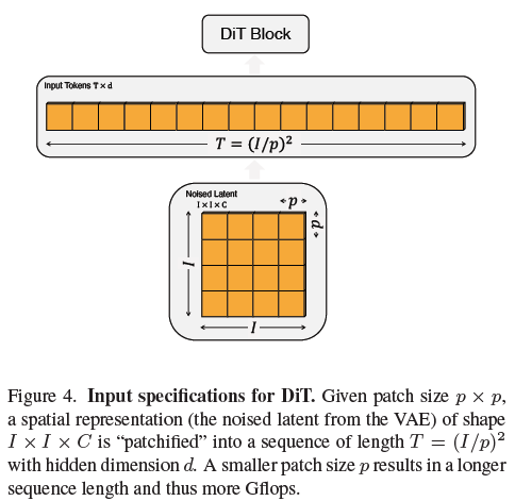 Patchify.
Patchify.
DiT는 Vision Transformer처럼 입력 이미지를 patch 단위로 분할하여 sequence로 처리한다. 입력 latent를 patch로 분할하고 각 patch를 flatten + linear embedding 한후 token sequence를 생성한다. 이때 patch size가 작아질 수록 token 수가 증가한다. 이에 따라 표현력은 상승하지만 연산량이 증가하는 특성을 가진다.
DiT는 다양한 conditioning 방식으로 transformer block을 구성하여 실험을 진행하였다.
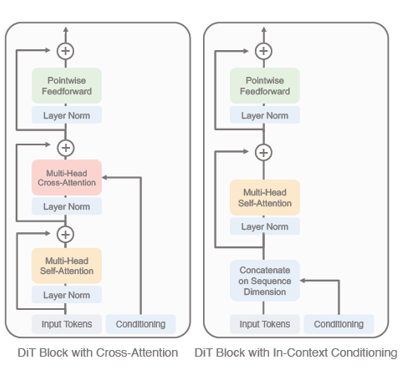 cross attention, in-context conditioning block.
cross attention, in-context conditioning block.
Cross-attention block
- timestep과 class embedding을 별도의 sequence로 생성
- Transforemr block안에 cross attention 구조를 추가
- 추가적인 Gflops는 들지만만 conditioning 효과는 좀 더 명확함
In-context conditioning
- timestep과 class label embedding을 CLS 토큰과 유사한 방식으로 추가
- 일반 ViT 스타일로 함께 transformer에 입력
- 별도의 cross-attention layer 없이 간단하게 구현 가능하다는 장점이 있음
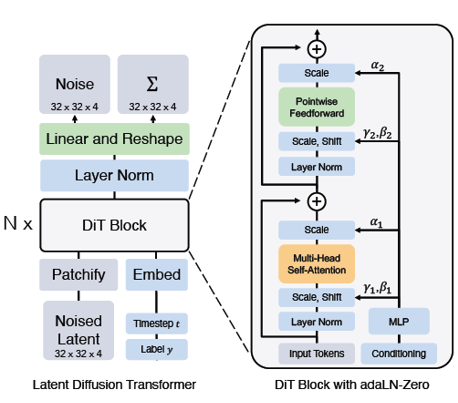 adaLN, adaLN-Zero block.
adaLN, adaLN-Zero block.
Adaptive layer norm (adaLN) block
- 일반적인 layer norm을 adaptive normalization layer로 교체
- timestep과 class 정보를 받아서 scale(γ), shift(β)를 동적으로 결정
- 적은 Gflops와 높은 계산 효율성을 보임
adaLN-Zero block
- adaLN을 확장해서, residual connection 직전 스케일 파라미터(α)를 추가
- 초기에는 α를 0으로 설정, 이후에 최적값으로 학습
- 학습 안정성이 대폭 향상되고, 최종 성능도 향상됨
기본적으로 normalization layer는 입력을 평균 0, 분산 1로 정규화 하는 과정을 의미하는데 이때 scale과 shift를 고정시킨다. 이때 Adaptive normalization은 scale과 shift를 timestep 정보, class conditioning 정보를 받아 동적으로 활용한다.
Experiment
DiT block result
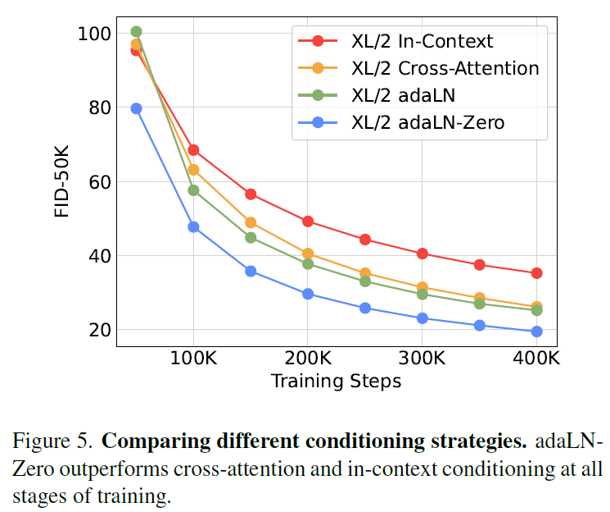 Comparing block.
Comparing block.
Ablation analysis
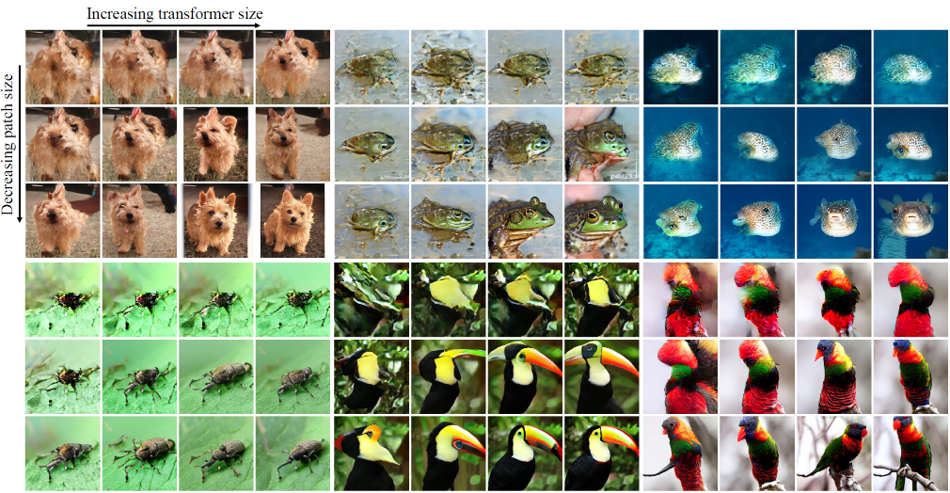 result visualize.
result visualize.
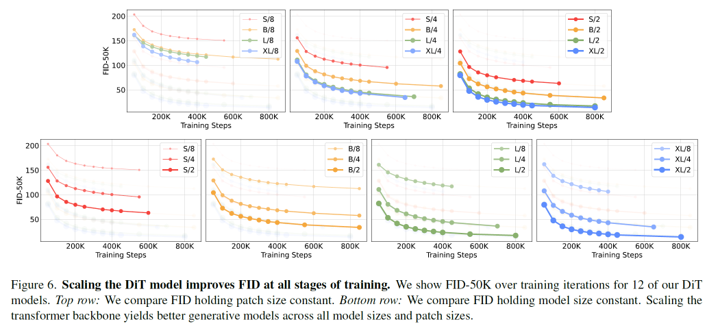 model scale.
model scale.
Transformer 크기를 키우거나, 더 많은 토큰을 사용하면, diffusion 모델의 성능(FID)이 전반적으로 좋아짐을 확인할 수 있다.
- 모델을 더 크게 만들면 (depth/width 키우기): Training iteration이 같아도 FID가 훨씬 낮아짐
- Patch size를 줄이면 (더 많은 token 사용): 모델 사이즈는 비슷하지만 성능이 더 좋아짐
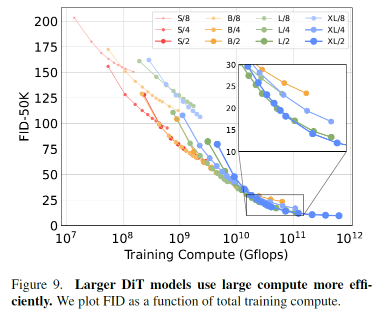 model size.
model size.
작은 모델은 아무리 오래 학습해도, 결국 큰 모델을 넘어설 수 없음을 보여준다.
- Training compute가 커질수록, 큰 DiT 모델이 훨씬 더 효율적임
Comparison
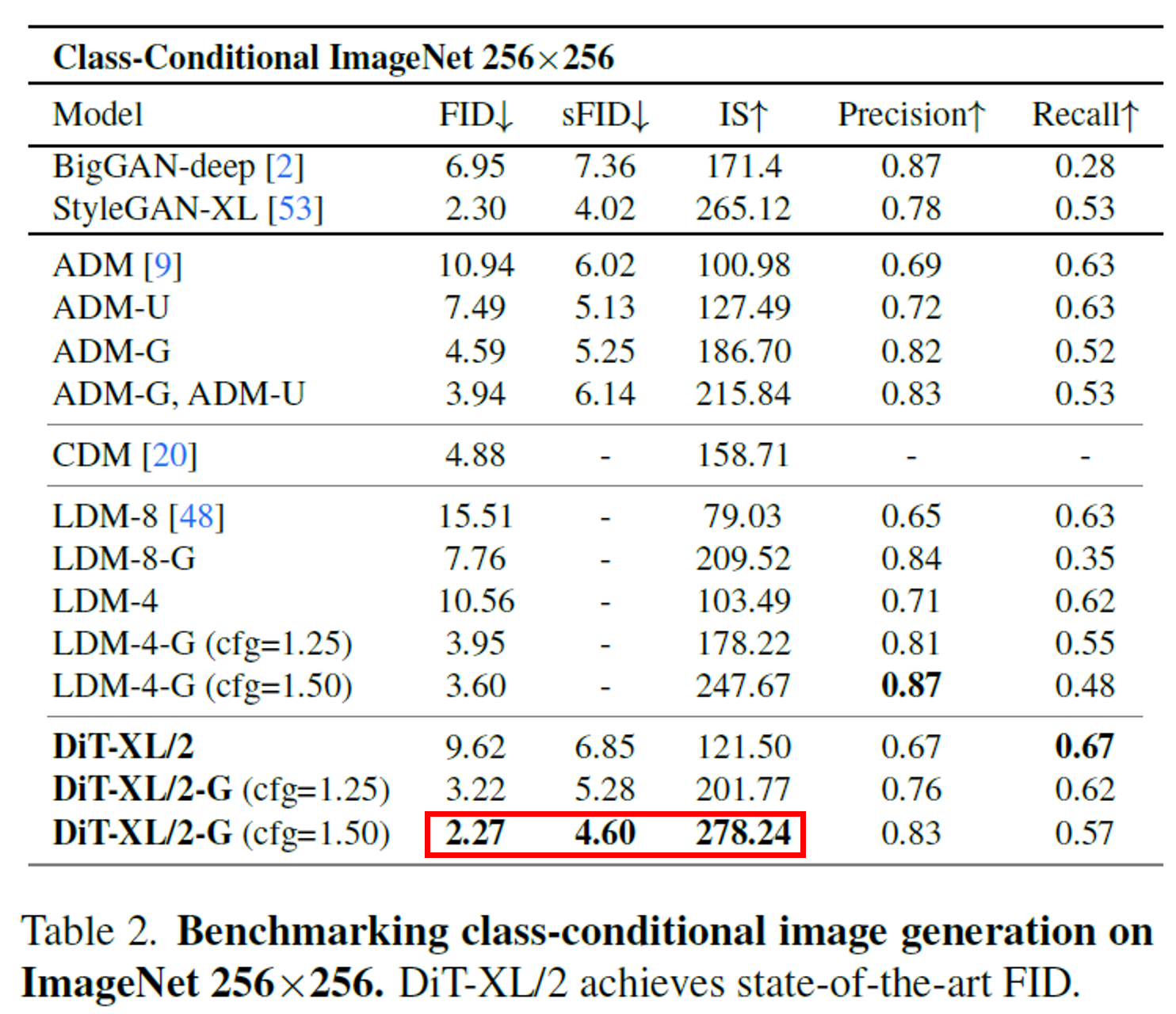 SOTA comparison.
SOTA comparison.
DiT는 U-Net을 쓰지 않고도 기존 SOTA를 넘어섬을 보여준다. Guidance를 적용했을 때 성능이 극적으로 올라간다.
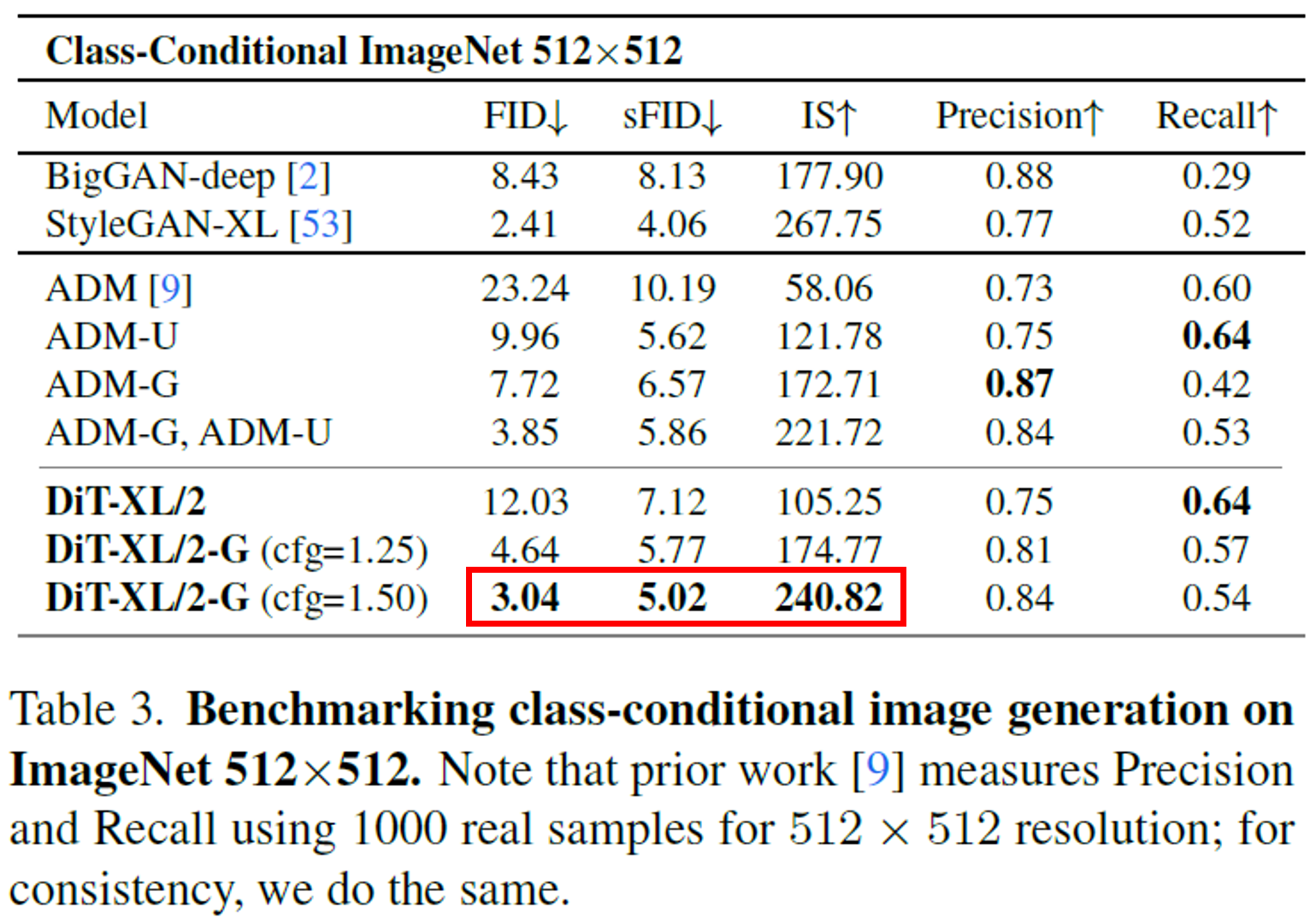 SOTA comparison.
SOTA comparison.
역시 guidance를 사용하면 성능이 크게 향상된다. 계산량(Flops) 대비 성능 효율성도 여전히 매우 뛰어남을 확인할 수 있다.
Conclusion
이번 논문에서는 기존 U-Net 기반 diffusion 모델을 Transformer로 대체한 Diffusion Transformer (DiT)를 제안했다.
DiT는 Vision Transformer(ViT) 구조를 diffusion model의 backbone으로 적용함으로써 U-Net의 inductive bias에 의존하지 않고도 고품질 이미지를 생성할 수 있음을 보여주었다.
- Transformer scaling law 적용
- DiT는 모델 크기, depth, token 수를 증가시킬수록 성능(FID, Inception Score 등)이 지속적으로 향상되는 scaling property를 확인
- 다양한 conditioning 방식 실험
- cross-attention, in-context conditioning, adaptive layer norm (adaLN), adaLN-Zero block 등의 다양한 transformer block design을 실험
- 그 중 adaLN-Zero block이 가장 연산 효율성과 성능 모두에서 우수함을 보여줌
- Latent Diffusion 적용
- high-resolution pixel space 대신 VAE latent space에서 diffusion을 수행하여 메모리와 계산 효율성을 높임