AdvDiff: Generating Unrestricted Adversarial Examples using Diffusion Models
AdvDiff 논문 리뷰
AdvDiff: Generating Unrestricted Adversarial Examples using Diffusion Models (arXiv)
Year : 2024
Author : Xuelong Dai et al.
ECCV
Introduction
Key Idea
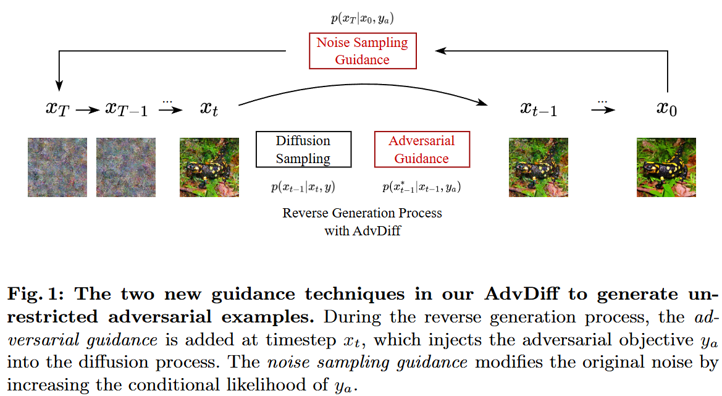 Fig 1. AdvDiff의 핵심 아이디어
Fig 1. AdvDiff의 핵심 아이디어
AdvDiff는 pre-trained diffusion model을 활용하여 Unrestricted Adversarial Examples (UAE)를 생성하는 새로운 공격 기법이다.
기존의 GAN 기반 공격 방법들은 저차원 latent space에 직접 gradient를 더하는 방식을 사용하여 다음과 같은 한계점들이 있었다:
- 이미지 품질 저하: latent space의 작은 변화가 생성된 이미지에 큰 왜곡을 초래
- Flipped-label 문제: 의도한 target class가 아닌 다른 클래스로 분류되는 현상 발생
- 불안정한 학습: GAN의 고질적인 mode collapse 및 학습 불안정성
이에 반해, AdvDiff는 확산 모델의 해석 가능한 확률적 샘플링 과정에 adversarial gradient를 세밀하게 삽입함으로써 다음의 장점을 제공한다:
- 자연스러운 이미지 생성 능력을 유지하면서도 높은 공격 성공률 달성
- 수식적으로 명확하게 정의된 공격 메커니즘
- Classifier-guided와 Classifier-fre 에 점진적으로 가우시안 노이즈를 추가한 후, 이를 역으로 복원하는 방식으로 학습되는 생성 모델이다.
Forward Process (노이즈 추가 과정)
Forward process는 깨끗한 이미지에 점진적으로 노이즈를 추가하는 과정이다:
\[q(\mathbf{x}_t \mid \mathbf{x}_{t-1}) := \mathcal{N}(\mathbf{x}_t; \sqrt{1 - \beta_t} \mathbf{x}_{t-1}, \beta_t \mathbf{I})\]여기서:
- $\mathbf{x}_{t-1}$ : 이전 timestep의 이미지
- $\mathbf{x}_t$ : 현재 timestep의 이미지
- $\beta_t$ : timestep $t$ 에서의 noise schedule (일반적으로 선형 또는 코사인 스케줄 사용)
- $\mathcal{N}(\mu, \Sigma)$ : 평균 $\mu$, 공분산 $\Sigma$ 를 갖는 가우시안 분포
이 수식은 이전 이미지에 약간의 노이즈를 추가해 다음 timestep 이미지를 생성하는 과정을 나타낸다. $\sqrt{1 - \beta_t}$ 는 원본 signal을 보존하는 계수이고, $\beta_t$ 는 추가되는 noise의 강도를 제어한다. Timestep $t$ 가 증가할수록 이미지는 점점 더 노이즈에 가까워 $$ (노이즈 제거 과정)
Backward process는 노이즈가 섞인 이미지를 깨끗한 이미지로 복원하는 denoising 과정이다:
\[p_\theta(\mathbf{x}_{t-1} \mid \mathbf{x}_t) := \mathcal{N}(\mathbf{x}_{t-1}; \mu_\theta(\mathbf{x}_t, t), \Sigma_\theta(\mathbf{x}_t, t))\]여기서:
- $\mu_\theta$ : 학습된 평균 예측 함수 (Neural Network로 구현)
- $\Sigma_\theta$ : 학습된 분산 예측 함수 (실제로는 대부분 고정값 사용)
- $\theta$ : 학습 가능한 모델 파라미터
이 과정은 노이즈가 섞인 이미지 $\mathbf{x}t$ 로부터 한 단계 덜 노이즈가 섞인 이미지 $\mathbf{x}{t-1}$ 을 예측한다. 이를 $T$ 번 반복하면 최종적으로 깨끗한 이미지 $\mathbf{x}_0$ 를 얻을 수 있
$$ DDPM의 학습 목표는 추가된 노이즈를 정확하게 예측하는 것이다:
\[L_{\text{DDPM}} := \mathbb{E}_{t \sim [1,T], \epsilon \sim \mathcal{N}(0, \mathbf{I})} \left\| \epsilon - \epsilon_\theta(\mathbf{x}_t, t) \right\|^2\]여기서:
- $\epsilon$ : 실제로 forward process에서 더해진 noise (ground truth)
- $\epsilon_\theta(\mathbf{x}_t, t)$ : 모델이 timestep $t$ 에서 예측한 noise
- $\left| \cdot \right|^2$ : L2 norm (Mean Squared Error)
DDPM의 핵심 아이디어는 이미지를 직접 복원하는 대신 노이즈를 예측하는 것이다. 예측한 노이즈를 $\mathbf{x}t$ 에서 제거하면 $\mathbf{x}{t-1}$ 을 얻을 수 있다. 이 방식이 이미지를 직접 예측하는 것보다 훨씬 안정적이고 효과적인 것으로 알려져 있
Loss Function
\[L_{\text{DDPM}} := \mathbb{E}_{t \sim [1,T], \epsilon \sim \mathcal{N}(0, \mathbf{I})} \| \epsilon - \epsilon_\theta(\mathbf{x}_t, t) \|^2\]- $\epsilon$: 실제로 더해진 noise (ground truth)
- $\epsilon_\theta(\mathbf{x}_t, t)$: 모델이 timestep $t$에서 예측한 noise
- $| \cdot |^2$: L2 loss (MSE)
Classifier-guided guidance는 별도로 학습된 classifier $p_\phi(y \mid \mathbf{x}_t)$ 를 사용하여 특정 클래스 $y$ 에 해당하는 이미지를 생성하는 기법이다:
\[\hat{\mu}_\theta(\mathbf{x}_t, t) = \mu_\theta(\mathbf{x}_t, t) + s \cdot \nabla_{\mathbf{x}_t} \log p_\phi(y \mid \mathbf{x}_t)\]여기서:
- $\mu_\theta(\mathbf{x}_t, t)$ : Diffusion 모델이 예측한 원래의 평균
- $s$ : guidance scale (클수록 클래스 조건이 강하게 반영됨)
- $\nabla_{\mathbf{x}t} \log p\phi(y \mid \mathbf{x}_t)$ : classifier가 클래스 $y$ 로 분류할 확률을 높이는 방향의 gradient Classifier-free guidance는 별도의 classifier 없이도 조건부 생성을 가능하게 하는 기법이다:
여기서:
- $\epsilon_\theta(\mathbf{x}_t \mid y)$ : 클래스 $y$ 가 조건으로 주어졌을 때 예측된 노이즈
- $\epsilon_\theta(\mathbf{x}_t \mid \emptyset)$ : 조건 없이 (unconditional) 예측된 노이즈
- $w$ : guidance weight (클수록 조건이 강하게 반영됨)
이 방법의 핵심은 conditional과 unconditional 예측의 차이를 증폭시키는 것이다. 학습 시 일정 확률로 클래스 정보를 제거하여 모델이 두 가지 모드로 작동하도록 학습시킨다. Classifier-guided 방식보다 구현이 간단하고 성능도 우수하여 최근 많이 사용되는 방법이 AdvDiff의 핵심 아이디어는 diffusion 모델의 reverse sampling process에 adversarial gradient를 주입하는 것이다. 이를 통해 자연스러운 이미지를 생성하면서도 target classifier를 속일 수 있다.
1. Reverse Process에 Adversarial Gradient 주입
일반적인 diffusion sampling 과정은 다음과 같다:
\[\mathbf{x}_{t-1} = \mu(\mathbf{x}_t, y) + \sigma_t \epsilon\]AdvDiff는 여기에 adversarial guidance를 추가한다:
\[\mathbf{x}_{t-1}^* = \mathbf{x}_{t-1} + \sigma_t^2 s \cdot \nabla_{\mathbf{x}_{t-1}} \log p_f(y_a \mid \mathbf{x}_{t-1})\]여기서:
- $\mathbf{x}_{t-1}$ : 원래의 denoising 결과
- $\mathbf{x}_{t-1}^*$ : adversarial gradient가 적용된 결과
- $y_a$ : 공격 목표(target) 클래스
- $p_f(y_a \mid \mathbf{x}_{t-1})$ : target classifier $f$ 가 클래스 $y_a$ 로 예측할 확률
- $s$ : adversarial guidance scale
- $\sigma_t^2$ : timestep에 따른 분산 (noise level에 비례하여 gradient 적용)
작동 원리: Reverse sampling의 각 단계마다 target classifier가 의도한 클래스 $y_a$ 로 높은 확률을 출력하도록 gradient를 계산하여 샘플을 조정한다. 이때 $\sigma_t^2$ 를 곱함으로써 초기(노이즈가 많을 때)에는 큰 변화를, 후기(이미지가 명확해질 때)에는 작은 변화를 주어 자연스러움을 \mathbf{x}_{t-1} = \mu(\mathbf{x}_t, y) + \sigma_t \epsilon $$Adversarial Prior 삽입
AdvDiff는 sampling의 시작점인 initial noise에도 adversarial 정보를 주입할 수 있다:
\[\mathbf{x}_T = \left(\mu(x_0, y) + \sigma_T \epsilon\right) + \sigma_T^2 a \cdot \nabla_{x_0} \log p_f(y_a \mid x_0)\]여기서:
- $x_0$ : 원본 이미지 (공격하려는 입력)
- $\mathbf{x}_T$ : diffusion sampling의 시작점 (가장 노이즈가 많은 상태)
- $a$ : initial noise guidance scale
- $\mu(x_0, y)$ : forward process를 통해 얻은 $x_0$ 의 noisy 버전
- $\sigma_T$ : 최종 timestep $T$ 에서의 noise level
작동 원리: 순수한 가우시안 노이즈 $\mathcal{N}(0, \mathbf{I})$ 에서 시작하는 대신, 원본 이미지 $x_0$ 를 forward process로 노이즈화한 후 adversarial gradient를 추가한다. 이를 통해 sampling 과정 전체가 처음부터 target class 방향으로 진행되도록 유도한다.
두 가지 전략의 결합:
- Initial noise injection은 전체적인 방향을 설정 이미지의 자연스러움을 더욱 향상시키기 위해 Total Variation (TV) regularization을 추가로 적용할 수 있다:
여기서:
- $m_{ij}$ : 위치 $(i,j)$ 의 픽셀 intensity
- $m_{i+m,j+n}$ : 주변 이웃 픽셀의 intensity
- 합은 3×3 이웃 영역에 대해 계산
역할: TV loss는 이미지의 공간적 부드러움(smoothness)을 측정한다. 이웃 픽셀들 간의 차이가 크면 TV 값이 커지고, 부드러운 이미지일수록 TV 값이 작아진다.
효과:
- 불필요한 high-frequency 노이즈 제거
- 경계선을 보존하면서도 전체적으로 부드러운 이미지 생성
- Adversarial gradient에 의한 부자연스러운 artifact 감소
- AdvDiff의 전체 과정_
알고리즘은 다음과 같이 진행된다:
- Input: 원본 이미지 $x_0$, 원본 클래스 $y$, target 클래스 $y_a$, pre-trained diffusion model, target classifier $f$
- Initial Noise 생성: Forward process를 통해 $x_0$ 를 $\mathbf{x}_T$ 로 변환하고 adversarial gradient 추가
- Reverse Sampling: $t = T$ 부터 $1$ 까지 반복:
- Diffusion model을 사용하여 $\mathbf{x}_{t-1}$ 예측
- Target classifier $f$ 의 gradient를 계산하여 adversariaNIST 데이터셋에서의 AdvDiff 생성 결과_
MNIST 실험에서 AdvDiff는 각 숫자를 다른 target class로 성공적으로 오분류시키면서도 원본과 유사한 시각적 품질을 유지한다.
 ImageNet 데이터셋에서의 AdvDiff 생성 결과
ImageNet 데이터셋에서의 AdvDiff 생성 결과
ImageNet과 같은 고해상도 자연 이미지에서도 AdvDiff는 사실적인 adversarial example을 생성한다. 생성된 이미지들은 육안으로는 자연스럽게 보이지만 classifier는 잘못된 클래스로 예측한다. Success Rates 비교 (Table 1, Table 2)_
Table 1: MNIST 데이터셋 결과 분석
Perturbation 기반 공격들 (PGD, BIM, C&W):
- 일반 모델에 대해서는 높은 공격 성공률 달성 (90% 이상)
- Adversarial Training (PGD-AT) 된 모델에 대해서는 공격 성공률 급감 (20% 미만)
- 이는 perturbation 기반 공격의 근본적인 한계를 보여줌
Unrestricted 공격들 (U-GAN, AdvDiff):
- 일반 모델뿐만 아니라 PGD-AT로 방어된 모델에 대해서도 높은 ASR 유지
- AdvDiff가 U-GAN보다 일관되게 우수한 성능 (약 5-10% 향상)
- 특히 defended model에서 AdvDiff는 86-88%의 높은 ASR 달성 실험 결과 (Table 5)_
Transferability 분석
Transfer Attack의 의미: 한 모델을 공격하기 위해 생성한 adversarial example이 다른 모델에도 효과가 있는지를 평가하는 실험이다. 이는 실제 black-box 공격 시나리오에서 중요한 지표다.
주요 결과:
- AdvDiff-Untargeted가 대부분의 모델에 대해 가장 높은 전이 성공률 달성 (70-85%)
- 다양한 아키텍처에 효과적:
- CNN 기반: ResNet, DenseNet 등
- Transformer 기반: BEiT, ViT-B, Swin Transformer 등이미지 품질 평가 (Table 3, Table 4)_
Table 3: 생성 품질 메트릭
Precision & Recall:
- Precision (정밀도): 생성된 이미지가 실제 데이터 분포에 얼마나 가까운지
- AdvDiff: 높은 precision → 생성된 adversarial example이 자연스러운 이미지 분포에 속함
- Recall (재현율): 실제 데이터 분포의 다양성을 얼마나 커버하는지
주요 기여
AdvDiff는 pre-trained diffusion model을 활용하여 고품질의 unrestricted adversarial example을 생성하는 새로운 공격 기법을 제시한다.
핵심 강점:
- 수식적 명확성: Classifier-guided diffusion의 원리를 adversarial attack에 적용하여 수학적으로 명확하게 정의됨
- 높은 공격 성공률: PGD-AT 등으로 방어된 모델에도 86-88%의 높은 ASR 달성
- 우수한 이미지 품질: 높은 SSIM, 낮은 LPIPS로 원본과 거의 구별 불가능한 자연스러운 이미지 생성
- 범용성: Classifier-guided와 classifier-free guidance 모두에 적용 가능
- 강력한 전이성: 다양한 모델 아키텍처(CNN, Transformer 등)에 대해 높은 transferability
의의
AdvDiff는 diffusion 모델의 확률적 샘플링 과정을 그대로 유지하면서 adversarial gradient를 세밀하게 주입함으로써, GAN 기반 방법의 한계(mode collapse, 품질 저하)를 극복했다. 이는 unrestricted adversarial attack 연구에 중요한 이정표가 되며, 동시에 현존 방어 기법들의 한계를 드러냄으로써 더 robust한 방어 메커니즘 개발의 필요성을 제기한다.
향후 과제
- Unrestricted adversarial attack에 대한 효과적인 방어 기법 개발 필요
- Diffusion 모델 자체를 robust하게 만드는 연구 필요
- 실제 환경에서의 공격 가능성 및 대응 방안 연구 Inception Score (IS):
- 생성된 이미지의 품질과 다양성을 동시에 측정
- AdvDiff가 U-GAN 대비 훨씬 높은 IS 달성 → 더 선명하고 다양한 이미지 생성
결론: AdvDiff는 GAN 기반 방법보다 훨씬 안정적이고 고품질의 adversarial example을 생성한다.
Table 4: 원본과의 유사성 메트릭
SSIM (Structural Similarity Index):
- 이미지의 구조적 유사성을 측정 (1에 가까울수록 유사)
- AdvDiff: 높은 SSIM → 원본 이미지의 구조를 잘 보존
LPIPS (Learned Perceptual Image Patch Similarity):
- 인간의 지각적 유사성을 deep feature로 측정 (낮을수록 유사)
- AdvDiff: 낮은 LPIPS → 인간이 보기에 원본과 매우 유사
의미:
- Adversarial example이 원본과 거의 구별할 수 없을 정도로 자연스러움
- 높은 공격 성공률을 유지하면서도 이미지 품질 저하 없음
- Unrestricted attack의 핵심: perturbation은 크지만 자연스러운 변형 의미:
- AdvDiff로 생성된 adversarial example은 모델에 구애받지 않는 robust한 공격 패턴을 학습
- 실제 환경에서 target model의 구조를 모르더라도 효과적으로 공격 가능
- Vision Transformer와 같은 최신 아키텍처에도 높은 공격 성공률 유지
이는 현존하는 대부분의 방어 기법이 AdvDiff와 같은 unrestricted attack을 완전히 방어하기 어렵다는 것을 시사한다
- 확장성: Diffuser 대비 대규모 데이터셋에서 더 안정적
주요 의미:
- Unrestricted adversarial attack이 perturbation 기반 공격보다 근본적으로 방어하기 어려움
- Diffusion 모델의 강력한 생성 능력이 adversarial attack에 효과적으로 활용됨
- 현존하는 방어 기법들이 AdvDiff와 같은 고품질 adversarial example에는 취약함 시작 노이즈 단계에서부터 adversarial signal을 주입해 sampling 전체 경로를 목표 label로 유도한다.
Regularization (Optional)
Total Variation (TV) Loss
\[TV(m_{ij}) = \sum_{m=-1}^{1} \sum_{n=-1}^{1} |m_{i+m,j+n} - m_{ij}|\]- $m_{ij}$: 이미지의 픽셀 intensity
- 주변 이웃과의 차이의 절댓값 합
TV는 이미지의 스무딩(smoothness)을 기법으로, 불필요한 노이즈 제거에 유리하다. AdvDiff가 추가할 수 있는 regularizer이다.
Algorithm
 Algorithm.
Algorithm.
Experiments
Visualization
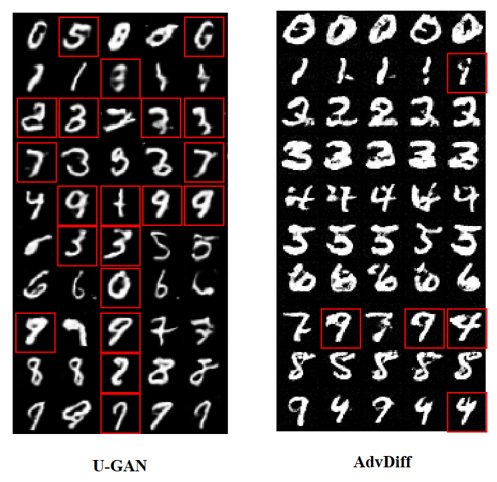 Mnist visualization.
Mnist visualization.
ImageNet visualization.
Attack Success Rates
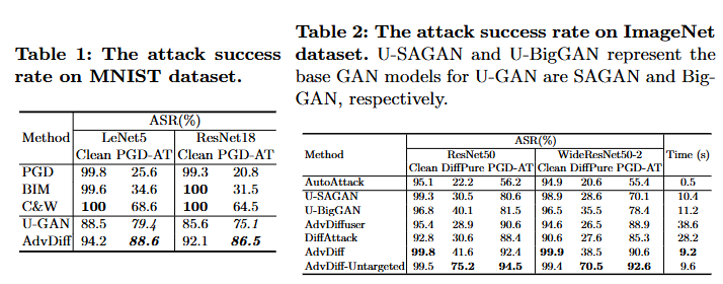 Attack success rates (Table 1, Table 2).
Attack success rates (Table 1, Table 2).
Table 1
- PGD, BIM, C&W는 perturbation 기반 공격이며, adversarial training (PGD-AT)된 모델에 대해 방어에 성공하는 모습을 보임 (ASR 급감).
- U-GAN과 AdvDiff는 unrestricted attack 방식으로, perturbation 공격보다 훨씬 높은 ASR 유지.
- 특히 AdvDiff는 U-GAN보다도 높은 ASR을 보여주며, MNIST에서도 강력한 성능을 입증.
Table 2
- AdvDiff는 모든 방어 기법에 대해 최고 또는 최상위 수준의 공격 성공률을 기록.
- U-GAN 대비 이미지 품질 향상, DiffAttack 대비 속도 향상, Diffuser 대비 효율성 우위.
AdvDiff가 PGD-AT처럼 방어된 모델도 AdvDiff는 86~88% 공격 성공률을 보이며 우회 가능함을 보여주며 ImageNet의 대규모 복잡한 분류 모델에도 우수한 공격 성공률과 효율적인 속도를 동시에 달성함을 보임
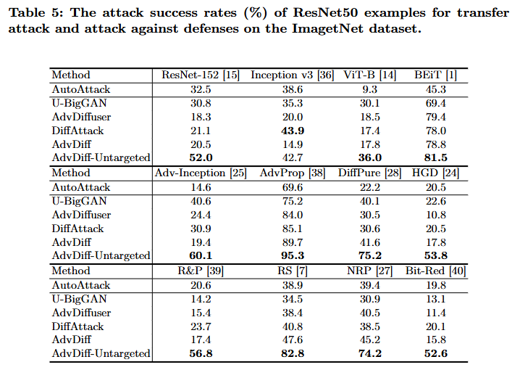 Transferability (Table 5).
Transferability (Table 5).
Table 5
- advDiff-Untargeted가 대부분의 모델에 대해 가장 높은 전이 성능을 보임.
- BEiT, ViT-B 같은 Vision Transformer 계열에도 잘 작동함
현존하는 대부분의 방어 기법조차 AdvDiff를 완전히 막지 못하며, 특히 untargeted 설정에서 압도적인 우회 성공률을 보임.
Image Quality
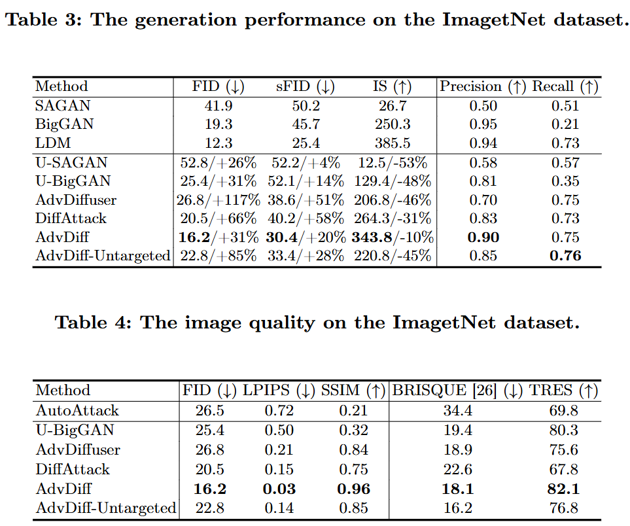 Image Quality (Table 3, Table 4).
Image Quality (Table 3, Table 4).
AdvDiff는 U-GAN 대비 훨씬 높은 precision과 IS, 그리고 적절한 recall로 시각 품질을 유지하면서도 공격 효과를 높이며 거의 원본 수준의 품질(높은 SSIM, 낮은 LPIPS)을 유지하면서도 공격 효과를 달성함을 보임
Conclusion
AdvDiff는 diffusion 모델의 확률적 샘플링을 그대로 유지하면서 공격 목적의 gradient를 세밀하게 주입함으로써 unrestricted adversarial example을 생성한다. AdvDiff는 수식 기반으로 해석 가능하며, classifier-guided / classifier-free guidance 모두 적용할 수 있는 구조를 가진다.